Using Machine Learning for Predictive Maintenance Tasks
Introduction:
In this blog post we will be looking at a synthetic dataset that "reflects real predictive maintenance encountered in the industry". Our goal is to predict the conditions that cause a machine to fail based on factors like tool wear, torque, rpm, and temperature. Click here to see the source for this dataset. I will touch on the primary challenge I faced dealing with this dataset as well as what type of ML model seemed to show the most promise for this challenge.
I also need to emphasize that this was done as part of an educational curriculum for introducing people to machine learning. This means that I did not dive deep into things like dataset preprocessing and hyperparameter tuning to reach the results described here. With some more effort spent in these areas you should be able to achieve even better results.
Class Imbalance:
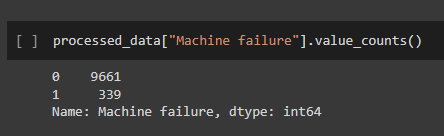
The main issue I encountered while using this dataset was class imbalance. Out of the 10,000 entries in the dataset, 9,661 showed no machine failure (indicated by a 0) while only 339 were examples of machine failure (indicated by a 1). This means that the event of interest to us only occurs about 3% of the time which can make it very difficult for the model to learn what conditions are likely to cause machine failures to happen.
In these situations it’s very important to go beyond the accuracy metric to judge the performance of a model. For example, I found that the first logistic regression models I trained would always achieve 97.4% accuracy. While this would make us believe our model is doing a great job, creating a confusion matrix from our model predictions tells a different story.
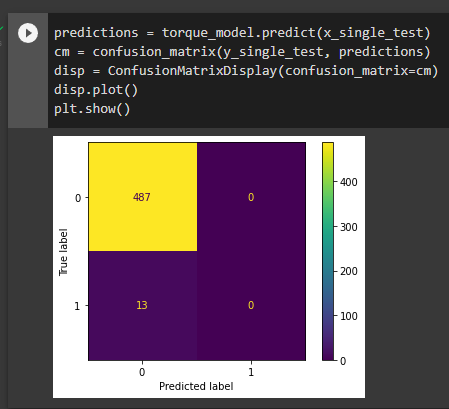
When we look in the 1 column on the Predicted label axis we can see that the model never even tried to predict a machine failure. This means the model missed predicting all 13 machine failures out of our 500 test samples. We can further confirm this behavior by dividing 13/500 which gives us 0.026. 1.00 - 0.026 = 0.974 which is the accuracy I would always achieve with this model. A model that never bothers to try to predict a machine failure is useless to us despite the high accuracy.
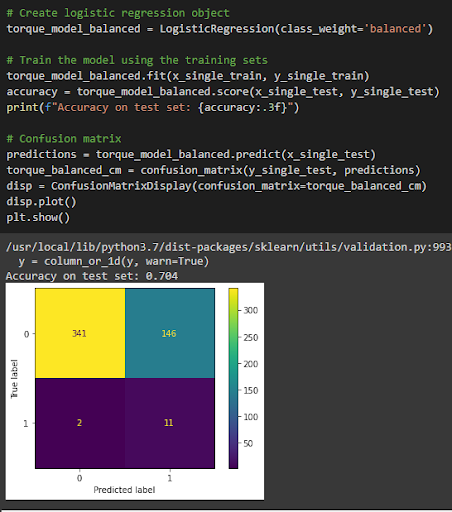
Luckily scikit-learn, the python library I was using for this model, has a handy feature that helps with this situation. By passing the argument class_weight=’balanced’ to our model when we initialize it we are able to tell the model to put more weight, or importance, on the class that is underrepresented in our sample. If you look at the confusion matrix produced after training the class balanced model we see much more promising results. The accuracy is now quite a bit lower at around 70%, however we see that the model is now predicting 1s as well as 0s. While this is only scratching the surface of techniques one can use to deal with class imbalance, changing this hyperparameter was a big move in the right direction for producing a useful model.
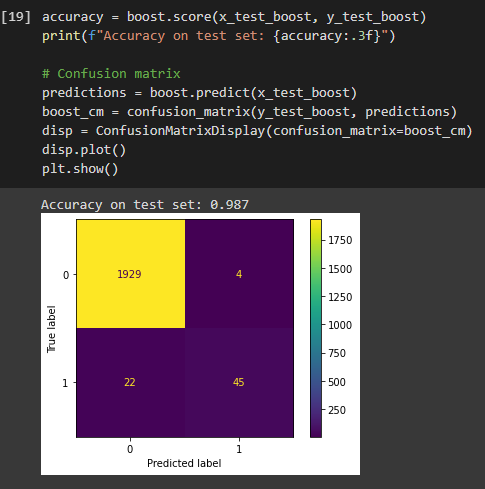
Model Type Performance:
As mentioned before, all the models I trained represented starting points rather than fully explored options for training a predictive maintenance model. However, from what I saw it seemed that the XGBoost model did the best job out of the box. In this instance it achieved an accuracy of 98.7% and the confusion matrix showed that the model was able to predict the majority of machine failures in the test dataset without making a ton of incorrect guesses.