Fine-Tuning LLM AI Models with NVIDIA GPUs (Falcon-7B-Instruct)
While Colab is a great resource for getting started with ML/DL techniques, the hardware limitations of its free tier are a challenge when one is working with large language models. However, using the QLoRa (Quantized LLMs with Low-Rank Adapters) method, we can finetune relatively large LLMs with NVIDIA GPUs in Colab’s free tier.
QLoRa
To begin breaking down the QLoRa method we have to start with LoRa, or low-ranking adapters. This technique, which was presented by Hu et al. (2021), adds a small amount of additional parameters to an LLM model while freezing all of the original parameters. One can then finetune only the newly added parameters, known as adapters, which makes finetuning much more computationally approachable. By freezing the original parameters you are also less likely to experience “catastrophic forgetting” where the model forgets information it gained from its pretraining.
QLoRa (Dettmers et al., 2023) is able to reduce the memory requirements even further by adding quantization to the mix. On a high level quantization reduces the size of each of the model’s parameters in memory by reducing the precision of the parameters’ values.
The combination of both of these strategies “reduces the average memory requirements of finetuning a 65B parameter model from >780GB of GPU memory to <48GB without degrading the runtime or predictive performance” according to Dettmers et al.
A good blog to read to learn more about QLoRa itself and the code required to run it is linked here.
Setup
For this example we are going to be using a sharded version of the Falcon-7B model (linked here). Having a sharded version of the model means that the checkpoints we have to load are split up into more pieces which allows us to load the model without running out of CPU RAM in our Colab instance.
Before you start make sure that you are using a GPU runtime in Google Colab.
We will first initialize our tokenizer which is fairly straightforward using the AutoTokenizer object from the Hugging Face Transformers library.

To quantize our model we will use the BitsAndBytes library. First we create our configuration for quantizing as seen below.
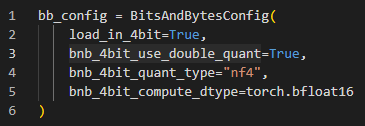
Then we should be able to load our Falcon 7B model into our Colab runtime as seen below. This will take a while to run as it downloads all the weights that make up our model.
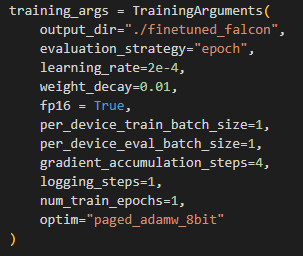
Next we can set up our arguments for the training process. I set these as seen below.
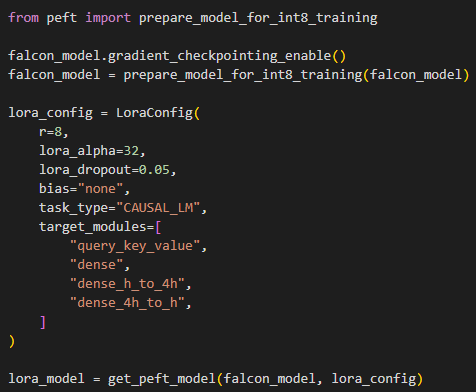
Then it’s time to set up our LoRa parameters for our model so we don’t have to train all of the model’s parameters. The code I used to do this can be seen below.
Once you have reached this step it is time to import and process the dataset you would like to use for finetuning. For this example I used the MedText dataset (linked here). The process for tokenizing a dataset in preparation for LLM finetuning is rather involved and I am going to revisit this in a future blog post. Once your dataset is tokenized and ready to use, you can set up the Transformers Trainer object in preparation for finetuning. The arguments I used for this can be seen below.
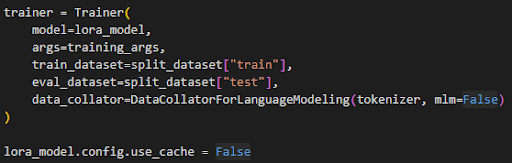
Then all that’s left is to start the training. Below you can see the code for starting training and saving the finetuned model.

In order to run for 1 epoch on an NVIDIA GPU the training took a little less than 3 hours while using 10.4 GB of GPU RAM.
Results
The MedText dataset I used for finetuning contains examples of patient symptoms paired with possible diagnosis for the patient. An example from the dataset can be seen below.
![]()

I tested the finetuning’s effect on the model by giving it the patient symptoms (the text in the first box) as the prompt and seeing how it answered. Even though we only trained the model for one epoch it produced results much more similar to the dataset diagnosis (the text in the second box) after the finetuning. Below are the responses from the model before and after finetuning (note I removed the repeated prompt from the response and both responses were capped at 100 tokens which is why it gets cut off at the end):
Base Falcon-7B Response:
(A) Ankle sprain (B) Ankle fracture (C) Ankle dislocation (D) Ankle fracture with dislocation (E) Ankle fracture with dislocation and ankle sprain Ankle sprain Ankle fracture Ankle dislocation Ankle fracture with dislocation and ankle sprain Ankle fracture with dislocation and ankle sprain Ankle fracture with dislocation and ankle sprain Ankle fracture with dislocation
Finetuned Falcon-7B Response:
This patient's symptoms and presentation suggest a lateral ligament sprain of the ankle (AKA inversion ankle sprain). Initial management should include immobilization to limit movement, ice and elevation of the
As you can tell the answer given by the finetuned model is much more in line with our actual diagnosis than the initial model’s response. The way the response is written is also much more cohesive and professional than the response given by the base model.