Running Falcon-40B-Instruct LLM Inference using Hugging Face Transformers (Generative AI)
Falcon-40B-Instruct (from here on referred to as Falcon) is an open-source instruction-following LLM (large language model). It is, at the time of writing, the highest scoring LLM on Hugging Face’s LLM Benchmarks leaderboard (https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard) making it the best open-source LLM currently available. Today we will be looking at running inference on this model using Hugging Face’s transformers library.
Most of the code used in the notebook is from the Hugging Face model card linked here (https://huggingface.co/tiiuae/falcon-40b ).
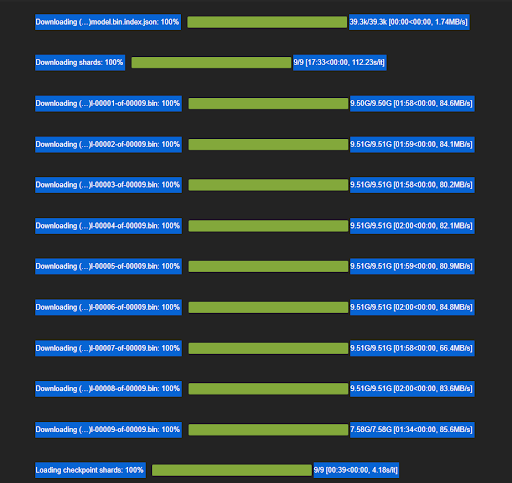
Note before you start that about 80GB of model files will be downloaded to run this model so make sure you have adequate room for this to happen. These files will be downloaded to ~/.cache/huggingface/hub/ by default but this can be changed to a path of your choice if storage space is an issue.
Before getting started install the necessary Python libraries for Transformers. I used Python 3.8.10 and the versions listed in the requirements.txt file which is available in my GitHub repo for this project. I found these library versions from the linked article by Eduardo Alvarez (https://towardsdatascience.com/running-falcon-on-a-cpu-with-hugging-face-pipelines-b60b3b8a32a3) .
The notebook itself is fairly straightforward. It utilizes Transformers’ Pipeline library which makes running inference using various Hugging Face hosted models fairly straightforward (https://huggingface.co/docs/transformers/pipeline_tutorial) . Start a Jupyter server and run all the cells in the notebook. This will take a while on your first run as it has to download some fairly large model files. These should be cached after the first run though so runtime of the notebook will be a lot faster after this initial download.
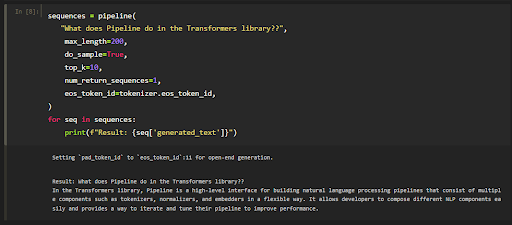
Once the whole notebook is run you can change the string passed in the last code cell to whatever question you would like to ask the model. The example used here is “What does Pipeline do in the Transformers library?”. To rerun with a different prompt you only need to rerun the last code cell, not the entire notebook. In this example you can see the model responded with
“In the Transformers library, Pipeline is a high-level interface for building natural language processing pipelines that consist of multiple components such as tokenizers, normalizers, and embedders in a flexible way. It allows developers to compose different NLP components easily and provides a way to iterate and tune their pipeline to improve performance.”
(Which is a reasonable response to our query)