Benchmarking Large Language Models (LLMs) – A Quick Tour
When working with LLMs one naturally wants to have a way to rank a model’s performance. This presents a challenge as LLMs are capable of various tasks and can be judged using many performance metrics. While being able to accurately answer prompts is important, other factors like model bias and overall coherence are also valuable to measure. Below is an overview of a few common datasets used as benchmarks:
ARC (AI2 Reasoning Challenge):
https://paperswithcode.com/dataset/arc
This dataset consists of questions from 3rd - 6th grade science exams. These are posed in multiple choice format and the dataset is split into two sections: “Easy” and “Challenge”. The two top models for this benchmark are currently GPT-4 and PaLM 2 respectively.
HellaSwag:
https://paperswithcode.com/dataset/hellaswag
https://rowanzellers.com/hellaswag/
https://arxiv.org/pdf/1905.07830v1.pdf
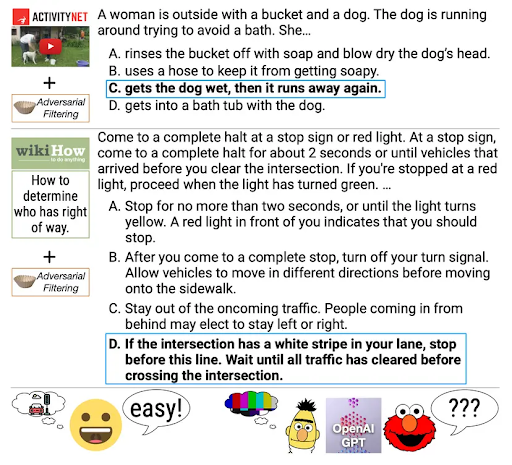
The HellaSwag dataset is also multiple choice but is meant to test common sense natural language inference rather than knowledge. It asks questions that are easy for humans to answer correctly but are purposely written in a way that trips up large language models. While older LLMs like BERT-Large and GPT were not able to achieve more than 50% accuracy, modern LLMs rival human performance with GPT4 achieving 95.3% accuracy and human accuracy being 95.6%. Below is a figure from the HellaSwag paper which provides an example from this dataset.
TruthfulQA:
https://arxiv.org/abs/2109.07958
https://paperswithcode.com/dataset/truthfulqa
LLMs are usually pretrained using data generated by humans on the internet. Not everything you see online is true and a concern with LLMs is that they will pick up misconceptions posted as truth by humans on the internet. TruthfulQA seeks to test for this by using questions crafted around common human misbeliefs.
MMLU (Measuring Massive Multitask Language Understanding):
https://arxiv.org/abs/2009.03300
https://paperswithcode.com/dataset/mmlu
https://github.com/hendrycks/test
This dataset is designed to test LLMs in 57 different subjects on a variety of difficulty levels, ranging from elementary to professional level difficulty. Examples of categories are mathematics, college computer science, economics, and astrology.
Final Thoughts:
We are still in the wild west of LLM benchmarks and performance leaderboards. There have been cases of popular benchmark datasets having incorrect data (https://www.surgehq.ai/blog/hellaswag-or-hellabad-36-of-this-popular-llm-benchmark-contains-errors ) and leaderboards having to reevaluate the implementation of their benchmarks which caused accuracy discrepancies (https://huggingface.co/blog/evaluating-mmlu-leaderboard ). At this point it is best to check a variety of leaderboards that use different benchmarks to get a holistic view of a model’s performance as well as remembering that for specific finetuned tasks manual review of a model may be more helpful than relying on general benchmarks.